Yigit DemiragI'm a Research Scientist at Google in Zürich. I focus on efficient and exotic neural computing hardware. I received my PhD from the Institute of Neuroinformatics of ETH Zürich. My advisors were Giacomo Indiveri and Melika Payvand. My PhD was focused on algorithm-hardware codesign for locality-optimized inference, training and routing on neural network accelerators built with in-memory computation. I also designed the course material and teached Spiking Neural Network on Neuromorphic Processors for undergraduate students at ETH Zürich.I did a few internships in the past, including a student researcher role at Google, working on bio-inspired quantized training with Blake Richards at MILA, modeling memristive memories at Advanced Technology Development Group of Samsung Electronics, implementing backpropagation on analog crossbar arrays at EPFL and SIMD optimization of monte carlo simulations at CERN. Email / CV / GitHub / Google Scholar / Twitter |

|
Selected Publications |
|
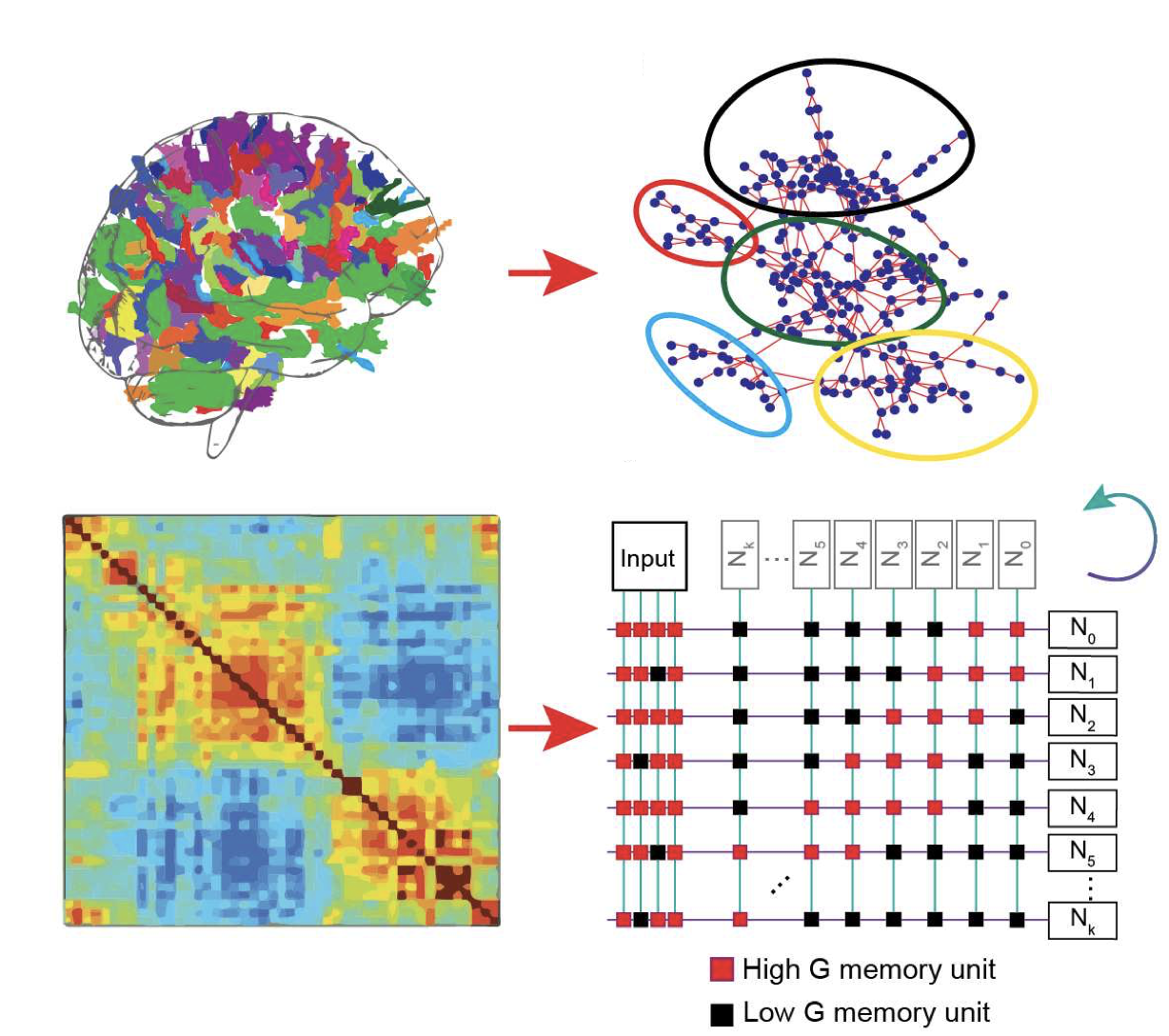
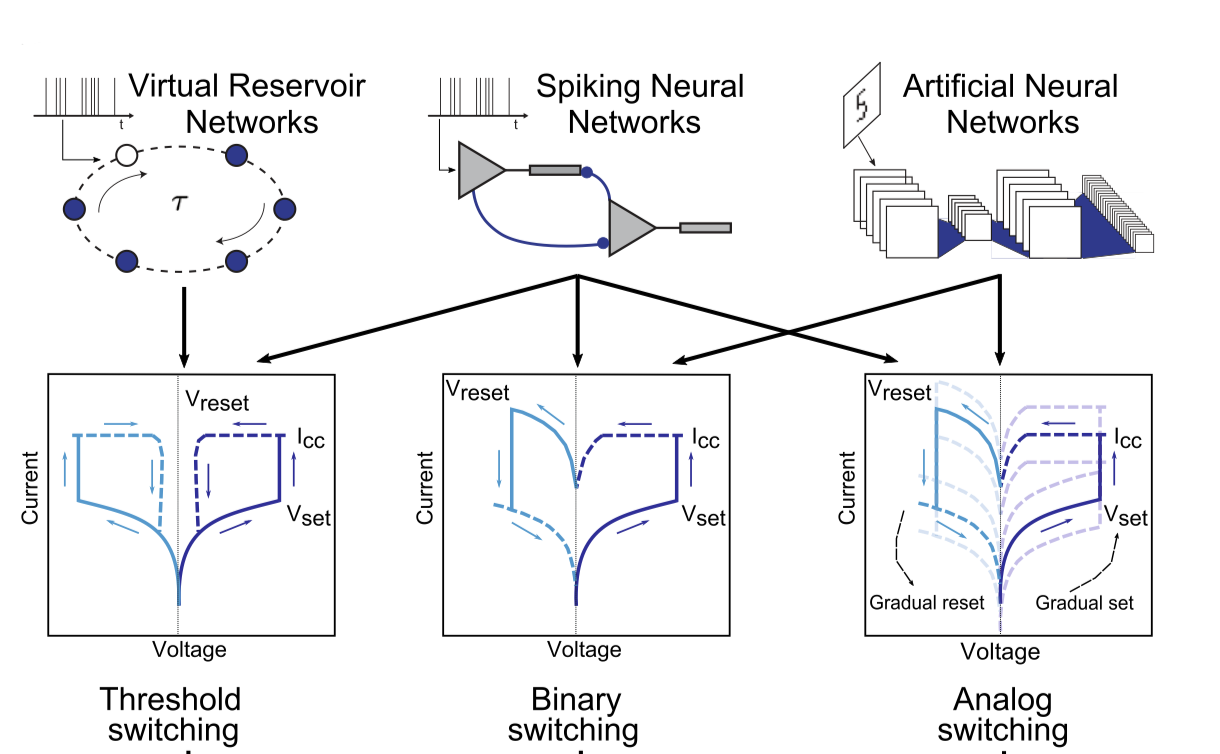
Mosaic: in-memory computing and routing for small-world spike-based neuromorphic systemsThomas Dalgaty*, Filippo Moro*, Yigit Demirag*, Alessio De Pra, Giacomo Indiveri, Elisa Vianello, Melika Payvand Nature Communications, 2024 paper / code |
|
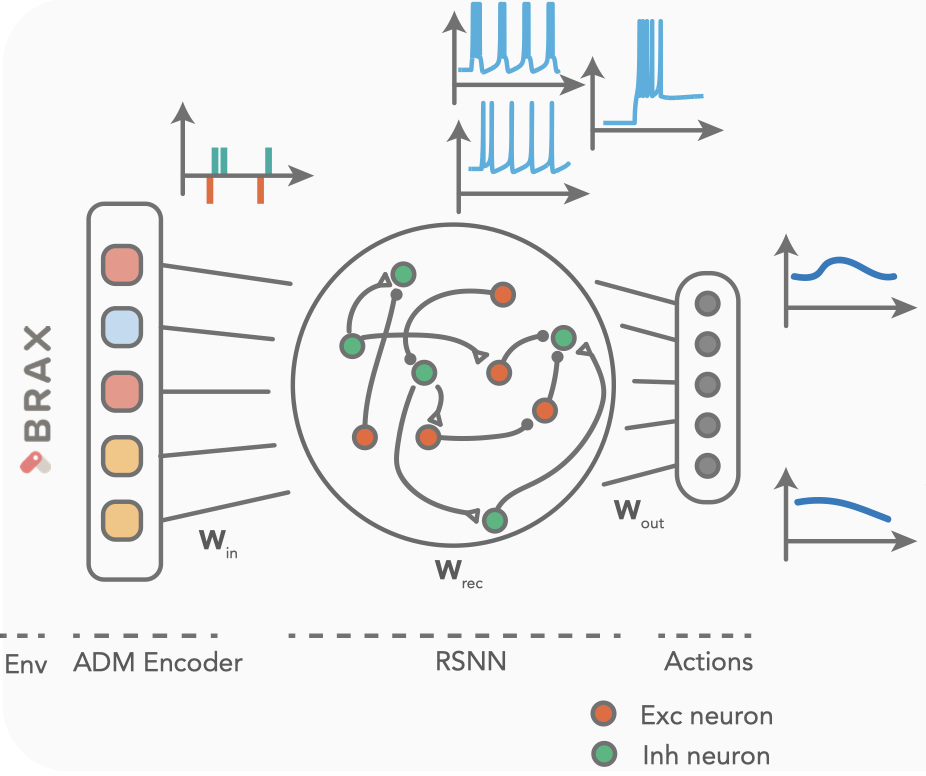
Network of biologically plasuible neuron models can solve motor tasks through heterogeneityYigit Demirag, Giacomo Indiveri Computational and Systems Neuroscience (COSYNE), 2024 |
|
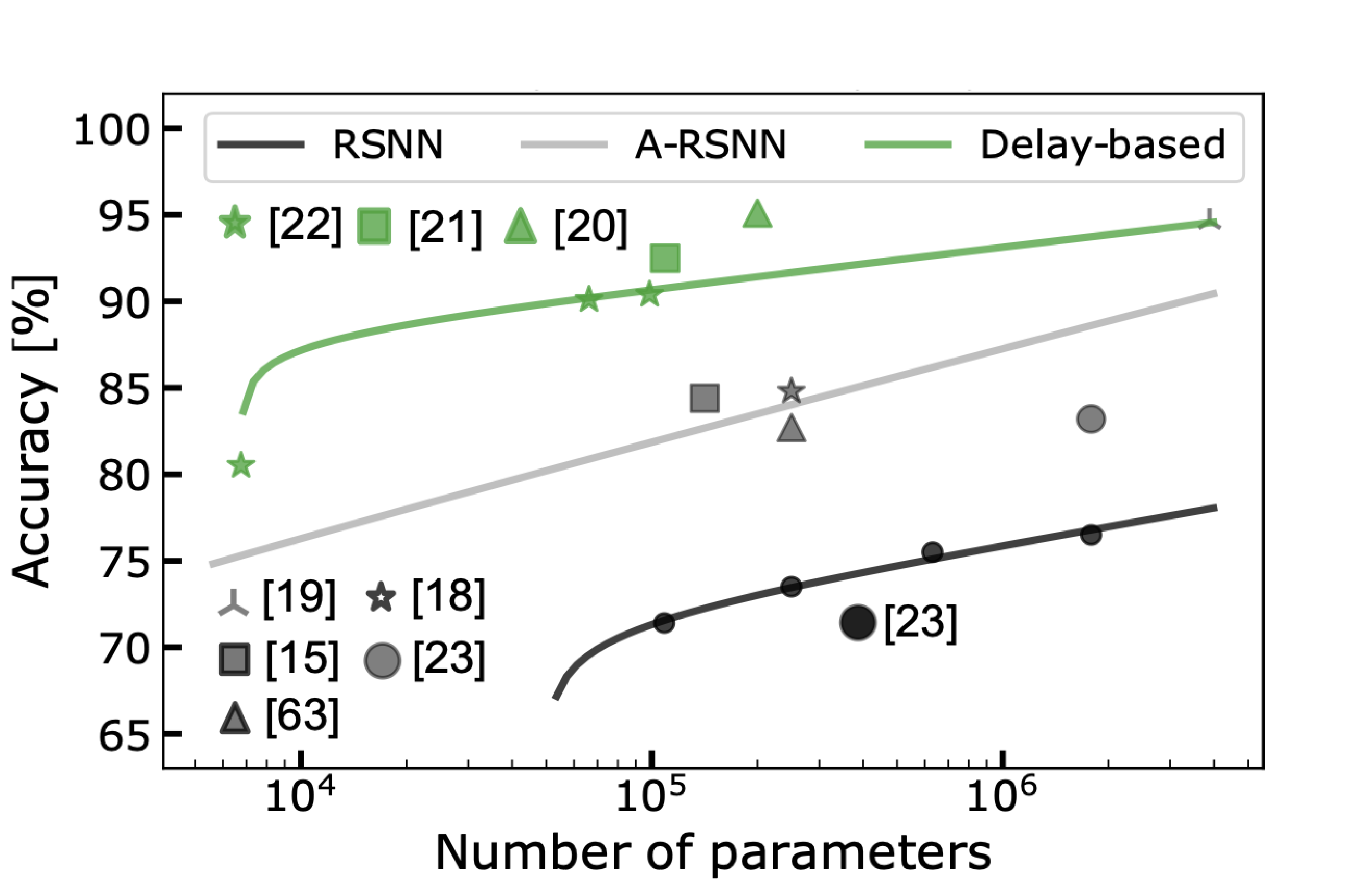
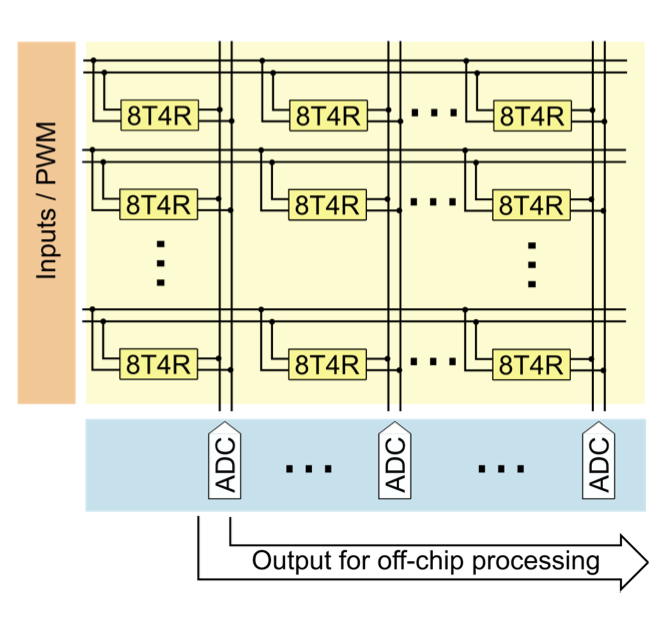
DenRAM: Neuromorphic Dendritic Architecture with RRAM for Efficient Temporal Processing with DelaysSimone D'Agostino*, Filippo Moro*, Tristan Torchet*, Yigit Demirag, Laurent Grenouillet, Niccolo Castellani, Giacomo Indiveri, Elisa Vianello, Melika Payvand Nature Communications, 2024 paper / code |
|
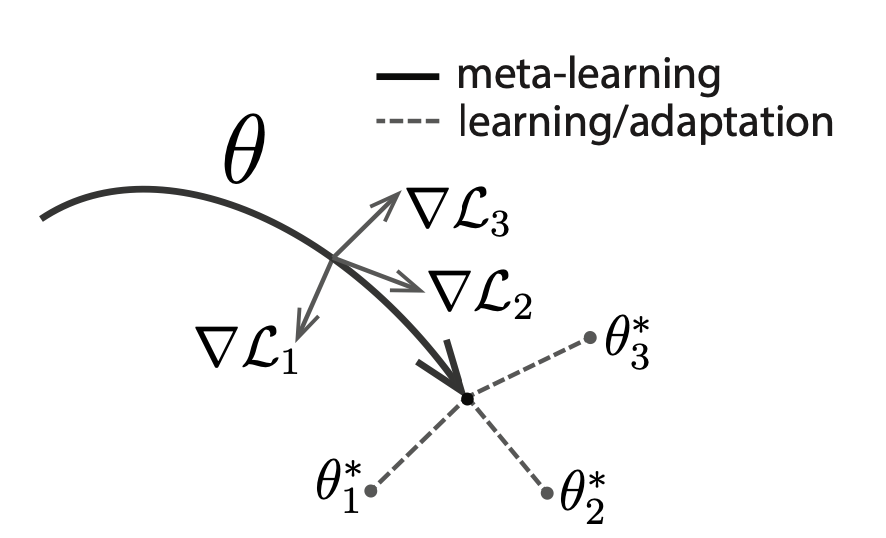
Overcoming phase-change material non-idealities by meta-learning for adaptation on the edgeYigit Demirag, Regina Dittmann, Giacomo Indiveri, Emre Neftci NeuMatDeCas (best run up oral contribution), 2023 code |
|
Reconfigurable halide perovskite nanocrystal memristors for neuromorphic computingRohit Abraham John*, Yigit Demirag*, Yevhen Shynkarenko, Yuliia Berezovska, Natacha Ohannessian, Melika Payvand, Peng Zeng, Maryna I Bodnarchuk, Frank Krumeich, Gökhan Kara, Ivan Shorubalko, Manu V Nair, Graham A Cooke, Thomas Lippert, Giacomo Indiveri, Maksym V Kovalenko Nature Communications, 2022 paper |
|
Biologically-inspired training of spiking recurrent neural networks with neuromorphic hardwareThomas Bohnstingl, Anja Surina, Maxime Fabre, Yigit Demirag, Charlotte Frenkel, Melika Payvand, Giacomo Indiveri, Angeliki Pantazi AICAS, 2022 paper / code |
|
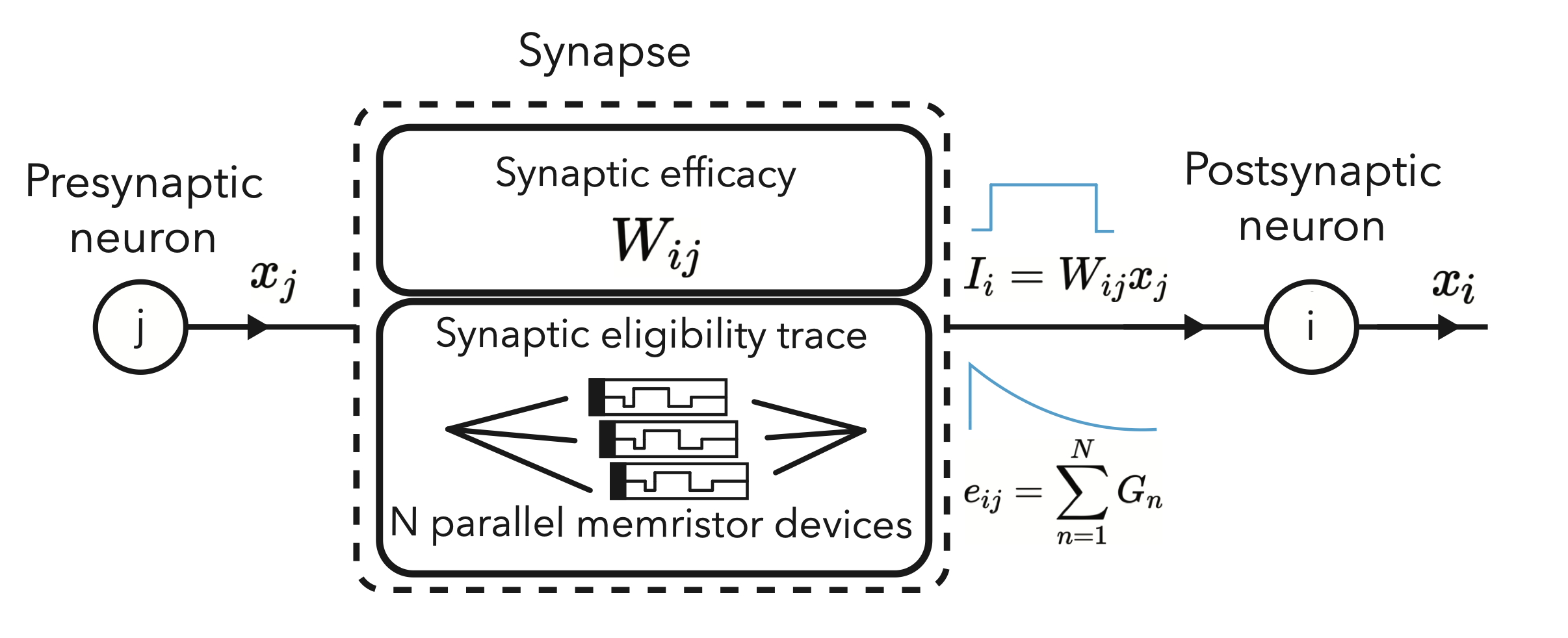
PCM-Trace: Scalable synaptic eligibility traces with resistivity drift of phase-change materialsYigit Demirag, Filippo Moro, Thomas Dalgaty, Gabriele Navarro, Charlotte Frenkel, Giacomo Indiveri, Elisa Vianello, and Melika Payvand ISCAS, 2021 paper |
|
Online training of spiking recurrent neural networks with phase-change memory synapsesYigit Demirag, Charlotte Frenkel, Melika Payvand, Giacomo Indiveri arXiv, 2021 paper / code |
|
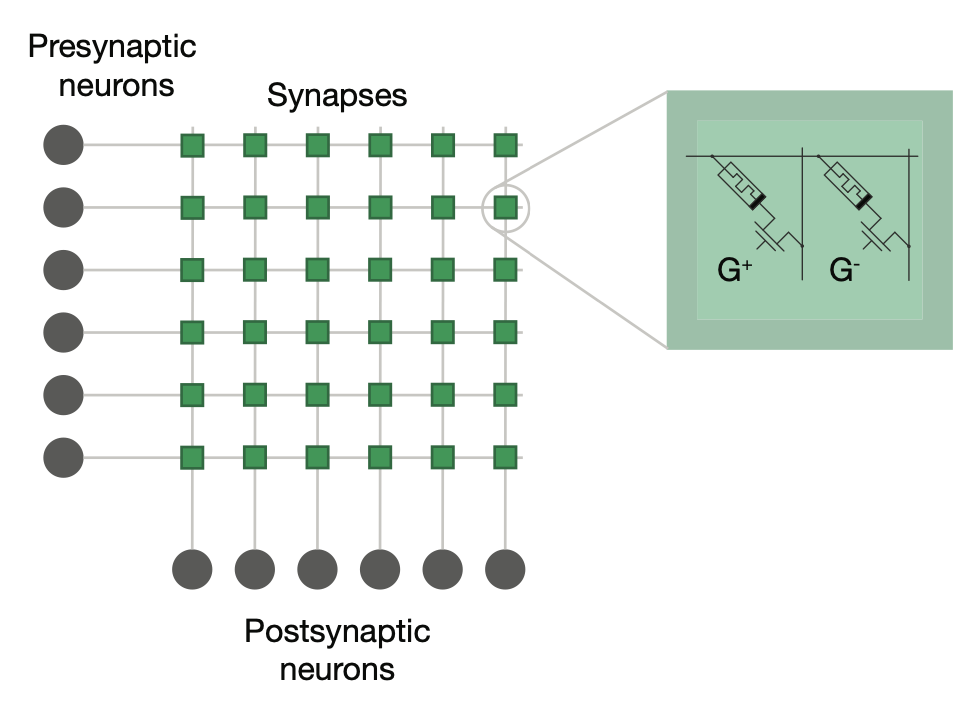
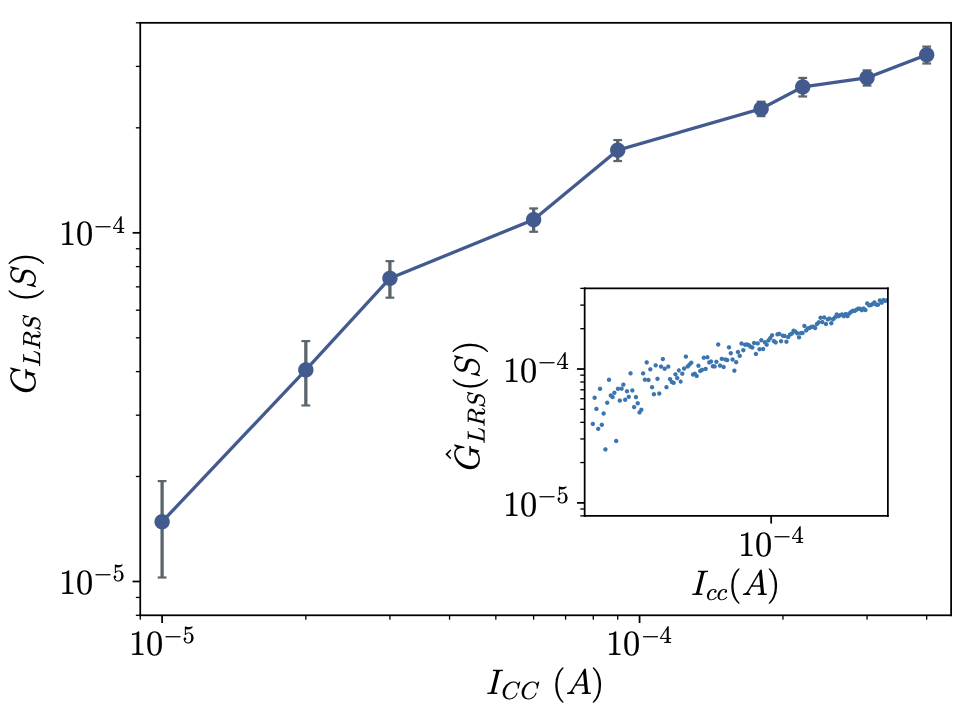
Analog weight updates with compliance current modulation of binary ReRAMs for on-chip learningMelika Payvand, Yigit Demirag, Thomas Dalgaty, Elisa Vianello, Giacomo Indiveri ISCAS, 2020 paper |
|
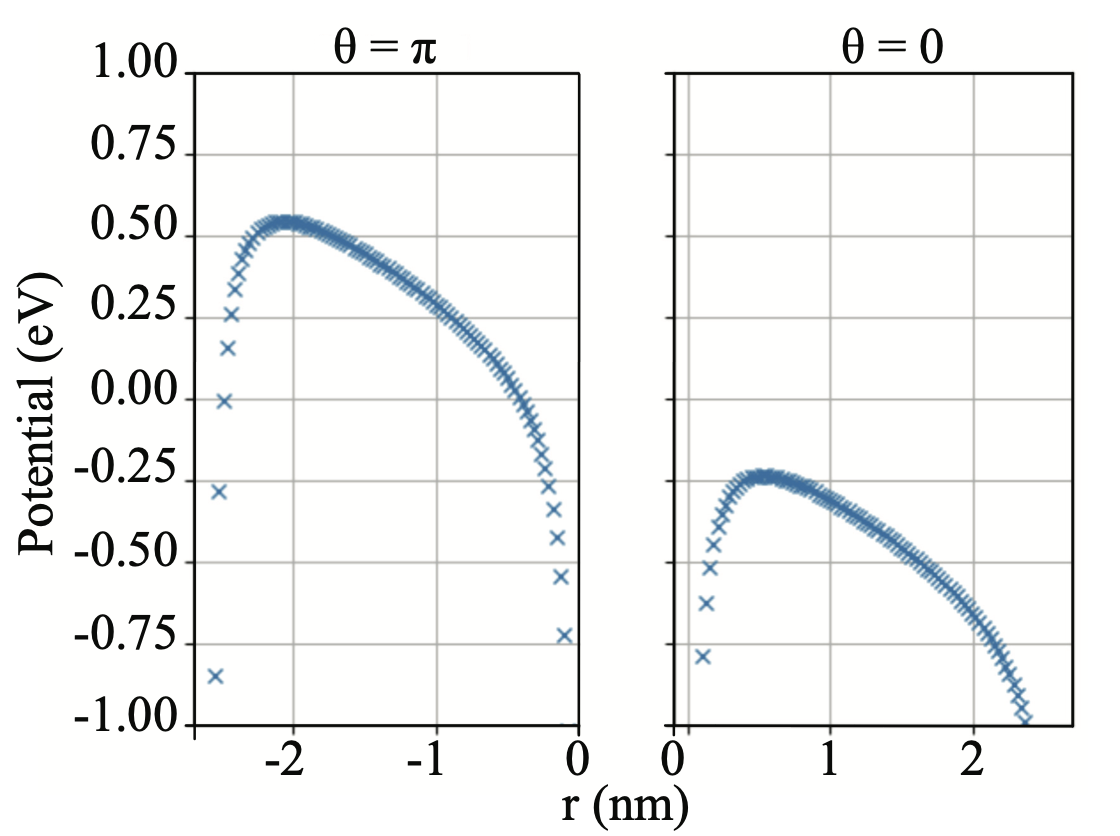
Modeling electrical resistance drift with ultrafast saturation of OTS selectorsYigit Demirag, Ekmel Ozbay, Yusuf Leblebici arXiv, 2018 paper |
|
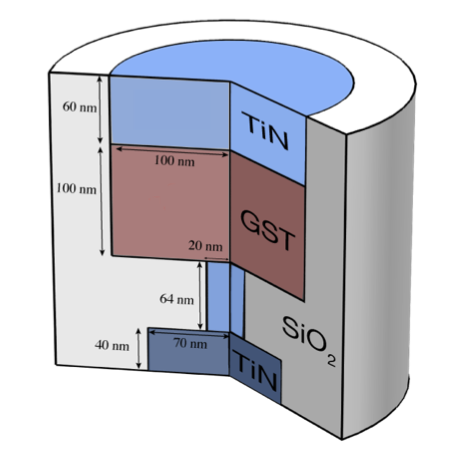
Multiphysics modeling of GST-based synaptic devices for brain inspired computingYigit Demirag Bilkent University, 2018 paper |
Open Source |

|
Gradients without BackpropagationJAX implementation of the Gradients without Backpropagation paper, which gets rid of backpropagation of errors and estimate unbiased gradient of loss function during single inference pass via perturbed Jacobian-vector product. code |
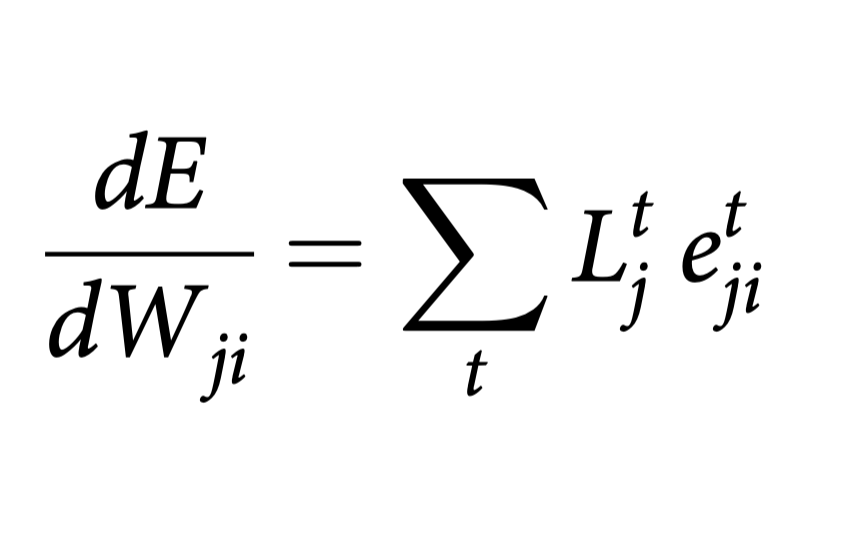
|
e-prop local learning rule for training recurrent networksJAX implementation of e-prop algorithm. It is written to be simple, clean and fast. I replicated the pattern generation task as described in the paper. code |
|
Dynap-SE1 Neuromorphic Processor SimulatorA minimal and interpretable Brian2 based DYNAP neuromorphic processor simulator for educational purposes. code |

|
Spiking Neural Network Simulator for TPUA simple Colab notebook for the training of recurrent spiking neural networks on TPU or multi-GPU settings. On a single A100 GPU, it can train a small size network of 512 LIF neurons via SHD dataset under <50 sec. code |
|
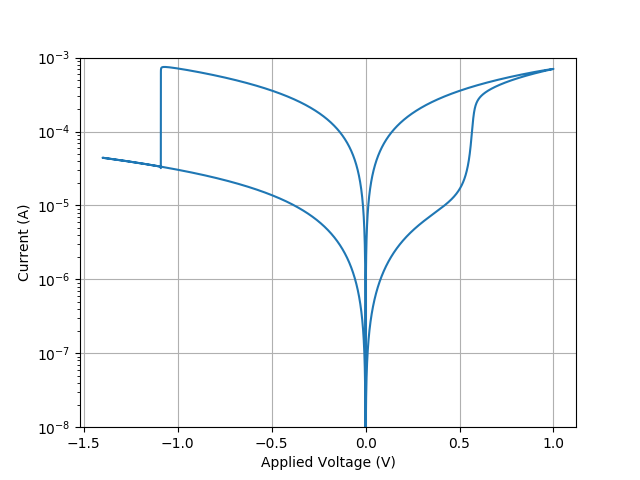
Physical model of HfO2/TiOx Bilayer ReRAM memory cellCompact model simulation of ReRAM cell. The model simulates IV characteristics of the cell, incorporating gradual SET and abrupt RESET processes. It considers filament geometry as a combination of plug and disc, and employs the Schottky barrier to represent the metal/oxide interface’s high work function, which depends on the oxide’s defect concentration. code |
|
2023 🪴 |